
Overview
2025 Summer
Have you ever said, “Yeah, I’ll follow up on that,” only to realize later that you never wrote it down? This happens to me from time to time. We forget not because we mean to. But because the act of capturing the reminder is a task in itself. You’re mid-conversation, momentum is flowing, and the last thing you want is to fumble around with your phone or ask Siri to take a note.
That made me wonder: what if reminders weren’t something you had to set? What if they could be inferred from what you were already saying?
So I built a fun project: a context-aware reminder agent for smart glasses. It worked across three layers: a perception layer (streaming audio, detecting speech, transcribing), an intelligence layer (an on-device LLM that extracts follow-up intent), and a data layer (context and reminder storage).
The shift here was subtle but powerful: instead of reminders being user-initiated, they became passive and context-driven — like an assistant quietly listening for the moments that matter.
As always, this was a personal educational project. Everything here was built on my own device, in my own time, using only public SDKs. The code and app won’t be distributed anywhere. In fact, all the code in this project was written by ChatGPT Codex under my guidance. This post is just about the ideas and what I learned along the way. Enjoy.
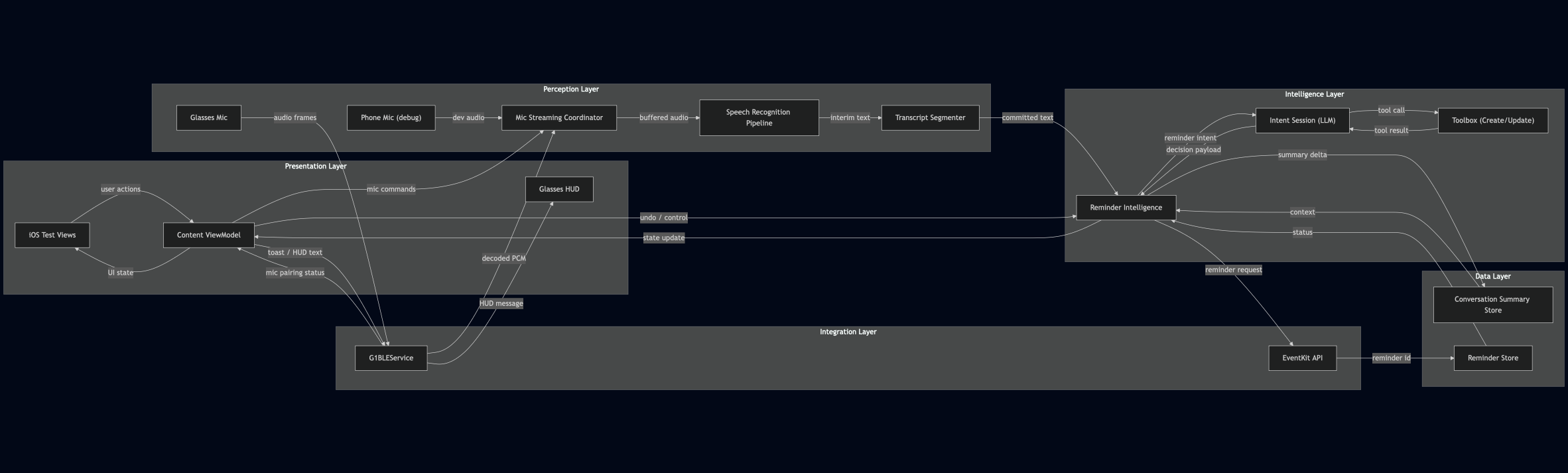
High-Level Architecture
The Problem
The core idea is deceptively simple: detect when someone makes a “reminder-worthy” statement in conversation, capture it. No friction, no typing, no “Hey Siri” incantations. It. Just. Works.
But designing for “simple” is rarely simple. I started out by writing down my requirements:
- On-device by default: Privacy mattered. So did latency and offline reliability. I didn’t want a cloud service streaming everything I said.
- Low distraction: This had to fit into the tiny HUD of glasses. Minimal UI, minimal interruptions.
- Low Latency: I want the reminder suggestion to appear as I’m finishing the sentence.
The moment you start writing these constraints down, you realize a naive approach (stream audio → feed it to an LLM → get reminders) isn’t going to cut it.
- Context window limits: You can’t really keep an LLM “always on”, how do you bright a continous audio stream to discrete LLM calls?
- Triggering: When exactly should the model be invoked? Every sentence? Every 30 seconds?
- Ambiguity: Natural language is messy and context matters. “I’ll get back to you in a few” — who’s “you”? when’s “a few”?
At the same time, I want to maintain modularlity, testability and maintability as with all my projects to ensure iteration speed. A single-shot pipeline wasn’t enough. I needed a layered architecture: one that could handle perception, reasoning, and storage separately, and then stitch them together into something coherent.
V0.1: Proof of Life on the Glasses
The first question I had to answer was embarrassingly basic: do these glasses even work for what I want?
I’m using the G1 Reality Glasses paired with my iPhone. For those who haven’t seen them before, they’re one of the rare smart glasses that actually look like normal glasses. The built-in monochrome display floats little bits of info in front of your eye (e.g. time, notifications, weather, and I have APPL stock showing at all time) basically a smartwatch glued to your face.
That’s the official pitch. But as a hacker, what grabbed me was a different question: what else can I make it display?
Luckily, under the hood the G1 is basically two microcontrollers talking over Bluetooth Low Energy (BLE). Somewhere on the internet I stumbled across a community-maintained Google Doc that listed out the device’s communication protocol. That was enough to start poking around.
So V0.1 was really just a proof of life. I wrote a Bluetooth manager, got text to render on the display (“hello world”), and even managed to pipe out microphone data.
There were plenty of hiccups. One fun discovery: the glasses actually run two microcontrollers, one per eye. Since the display has dual projectors, you have to send identical text packets to both controllers in sync, or one eye just goes blank. (But I guess you could intentionally send mismatching info to mess with people…) Same thing with the mic: there’s a pickup in each arm, and you can either grab one stream or combine them with some lightweight SNR (signal-to-noise ratio) or VAD (voice activity detection) processing. For now, I kept it simple and just used one side.
Once I had mic data flowing, the next step was obvious: speech recognition. Apple’s SFSpeechRecognizer API made it almost too easy to spin up on-device transcription. This became the perception layer of the system: raw audio in, rolling transcript out.

It works!
By the end of this phase I had a scrappy little test UI that streamed audio from the glasses and showed me a live transcript right on the HUD. It wasn’t glamorous, but it was a working foundation.
Here’s the architecture so far:
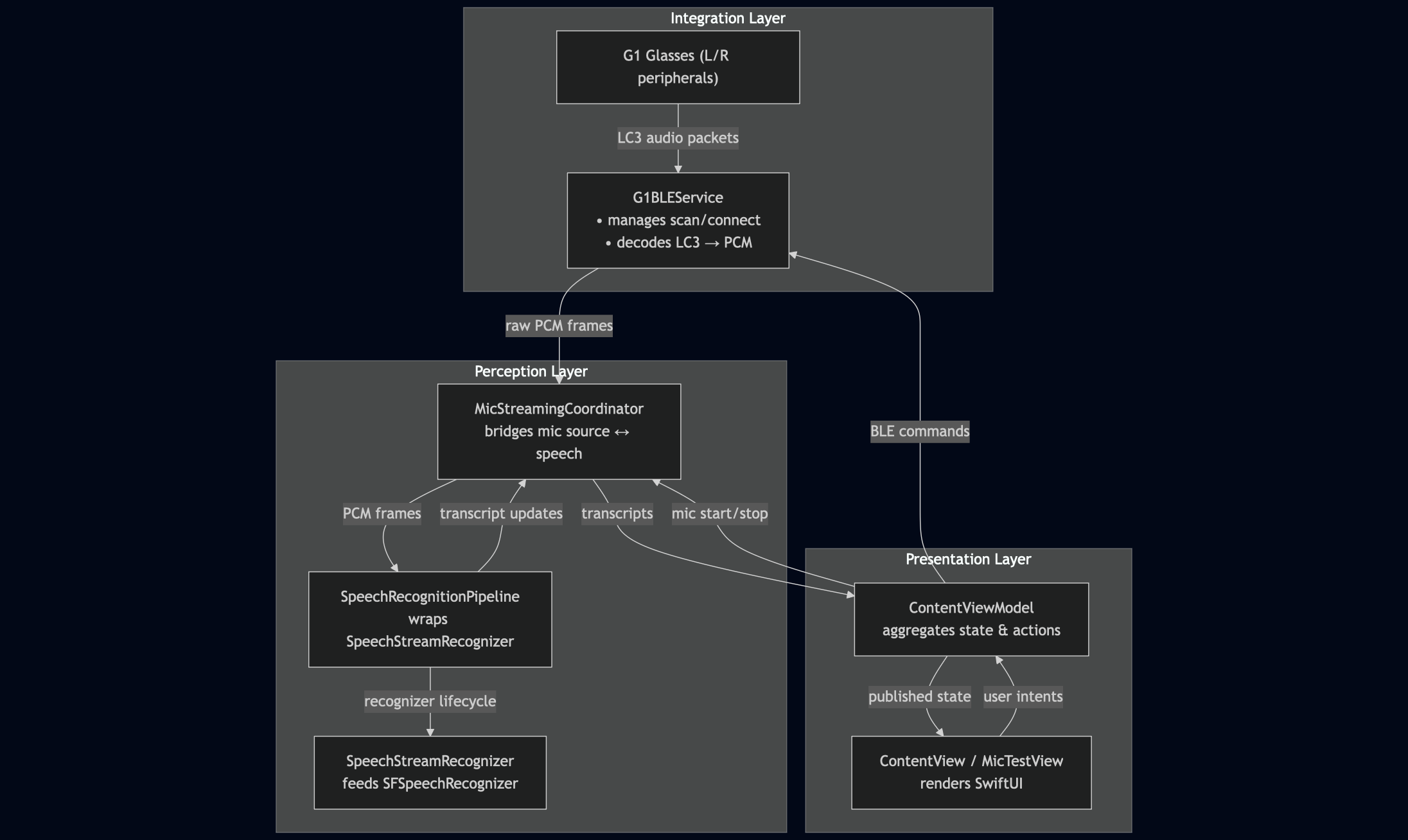
v0.1: Proof of Life on the Glasses
V0.2: Does the on-device LLM even work?
In June 2025, Apple dropped the Foundation Models SDK — a neat little API that lets developers call Apple’s on-device models directly. The default option is a ~3B parameter model. Small by today’s standards, but fast, private, and (supposedly) good enough for lightweight tasks. The question I had was: can it actually handle extracting reminders from natural conversation?
My goal here is to get the one-shot case working: feed it a few sentences and see if it could spit out a structured reminder. If I said, “Let’s check in with Chris about the deck tomorrow,” would it know to create a reminder for tomorrow: follow up with Chris on deck?
To keep things extendable, I modeled reminder creation as a “tool.” Right now the tool doesn’t do much, it just invokes a callback that updates the text on the glasses display. The idea is that the model decides when to call it, and later I can plug in real storage or notifications behind the same interface without changing the upstream logic.
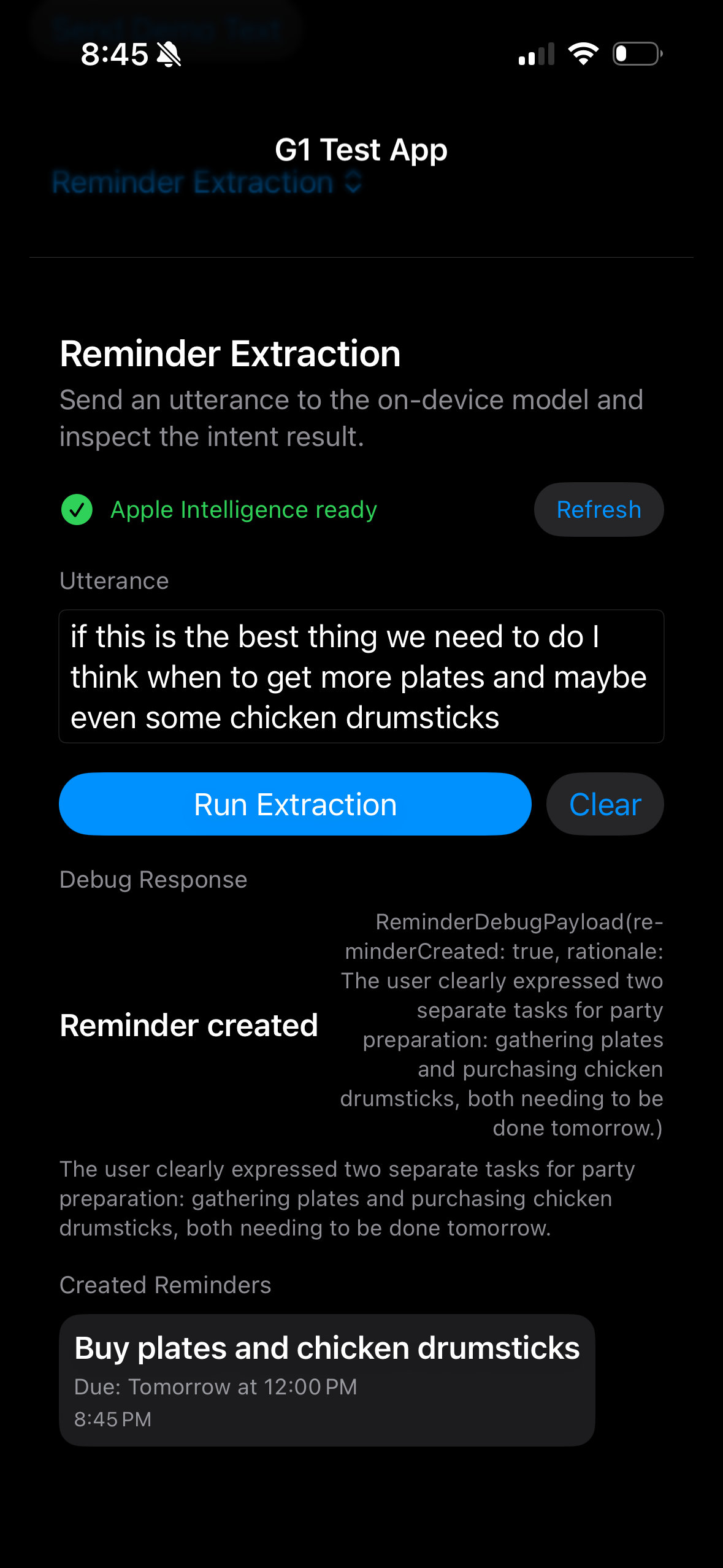
One-shot works!
And it works! The model is able to extract reminders pretty reliably. The main hiccup is false positives: sometimes it flags a random line with no reminder-worthy info. I suspect that’s more of a prompting issue than a model limitation. If I had more time and money, I’d want to build an automated test suite with another LLM as a judge: run a bank of sample conversations, measure precision/recall, and tune prompts until coverage feels solid.
One disappointment is I assumed the Foundation Models SDK would be a neat abstraction layer where I could swap in different models with almost no changes. Nope. At the moment, it only supports Apple’s on-device model. That’s fine for prototyping, but in production most people will run LLM processing and tool-calling logic on a server and pipe the results back over a socket. For me, it means I can’t easily benchmark other models side-by-side using the same interface. A little sad, but at least it’s a working baseline.
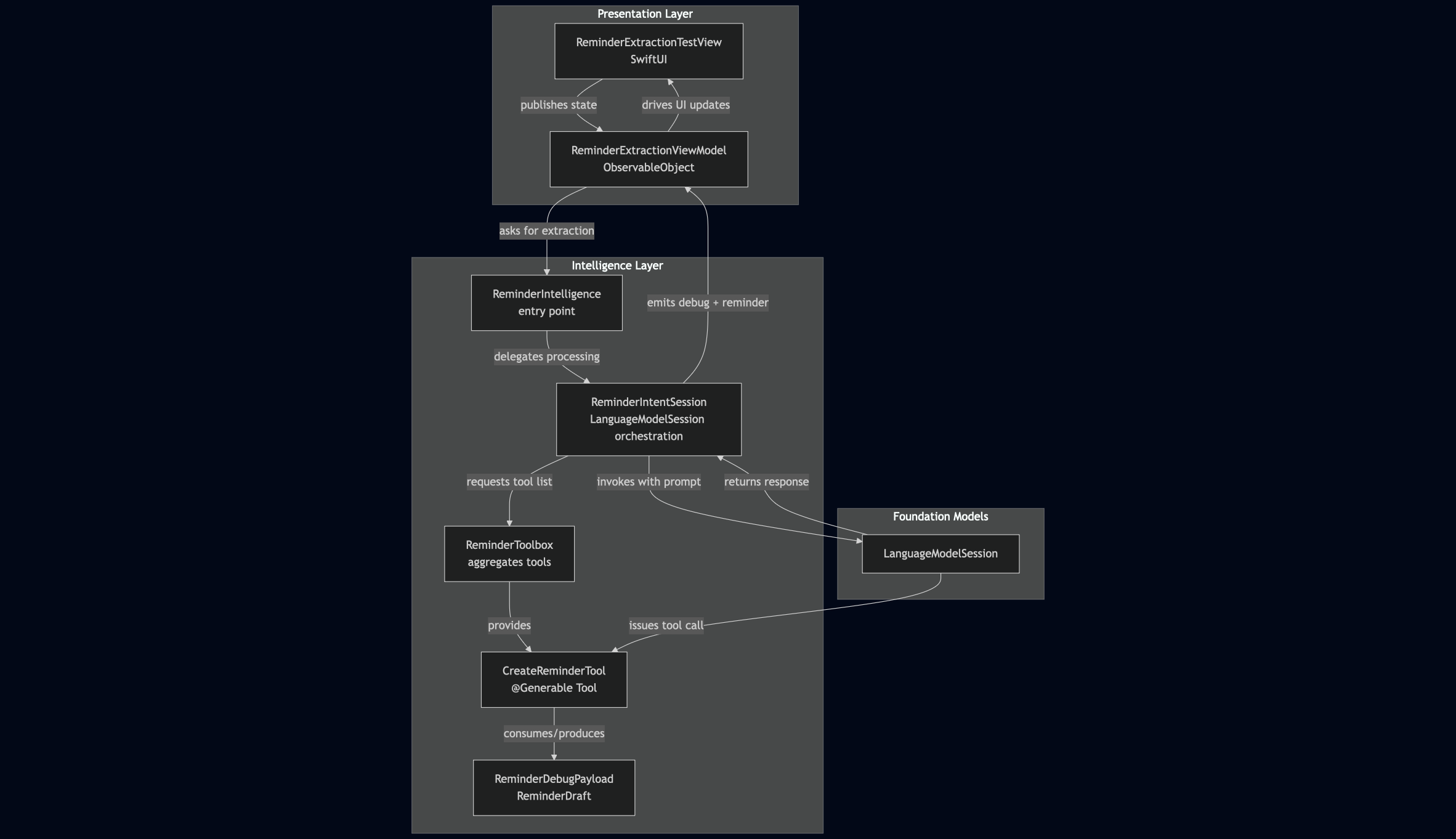
v0.2: Reminder Extraction
V0.3: Bridging Perception and Intelligence
Now that perception and intelligence both worked in isolation, the next step was connecting them. This is where the real design tension surfaced: speech recognizers emit noisy, continuous partials, while LLMs prefer stable, discrete chunks.
At first, I thought this gap would be easy — just figure out when the transcript was “good enough” to send downstream. In reality, it turned into a subtle design problem: how do you balance the recognizer’s constantly changing stream with the extractor’s need for clarity, without spamming it or chopping thoughts mid-sentence?
First attempt: complex heuristics
I tried reconstructing stability from the recognizer’s tokens: tracking per-word timing, buffering the last few tokens, waiting for punctuation prediction, measuring silence gaps, adding debounce windows. On paper, this gave me fine-grained control. In practice, it was a mess. The more logic I added, the more parameters I need to tune. And the more I tune them, the harder it is to find a good balance. Every tweak risked a regression.
Pivot: simple threshold
Instead of fighting the partials, I pivoted to using the recognizer’s own formattedString as a rolling buffer. Let it grow until it passes a threshold—either enough characters or enough idle time—then flush the whole thing. If the recognizer backtracks (the string suddenly shrinks), emit whatever’s there and reset. This approach is simpler, more reliable, and works with the recognizer’s built-in smoothing instead of against it.
The tradeoff is clear: sentences may get cut mid-thought. But for now, I decided that was acceptable. I can mitigate it by appending an overall conversational context and deduplicating similar reminders (details in the next section). It’s not perfect, but it unblocked progress.
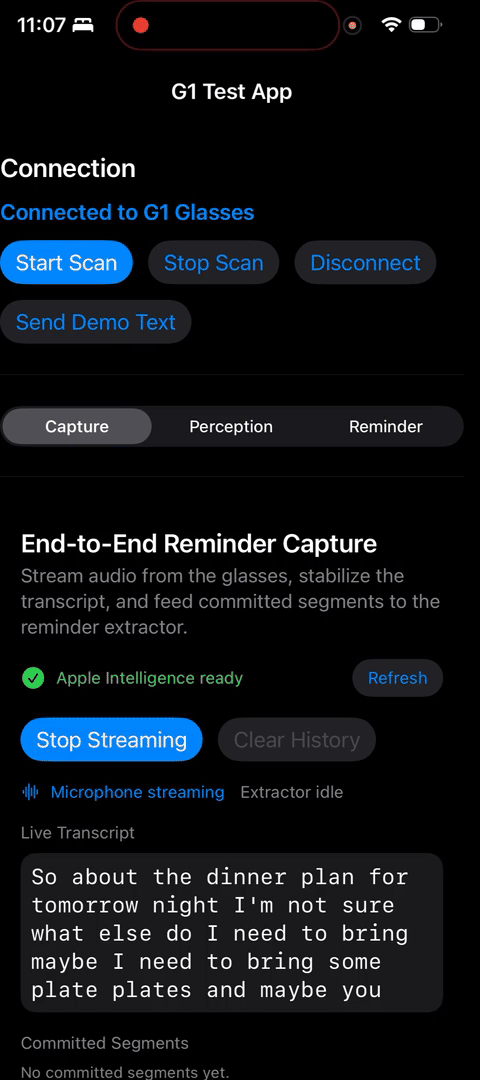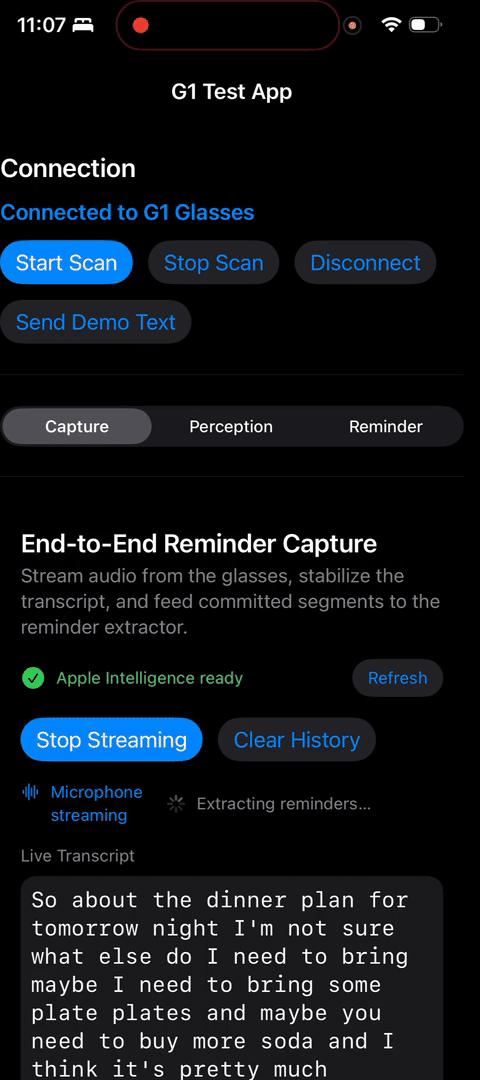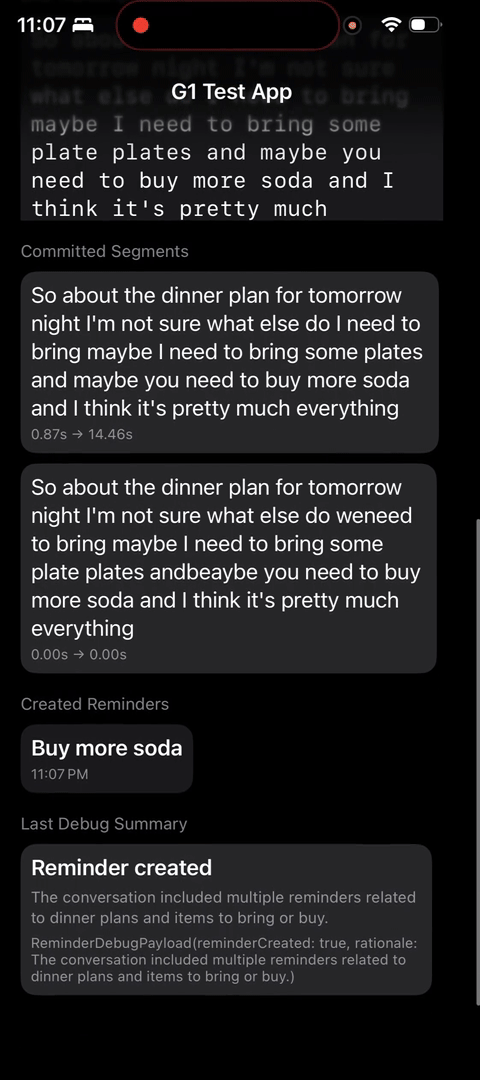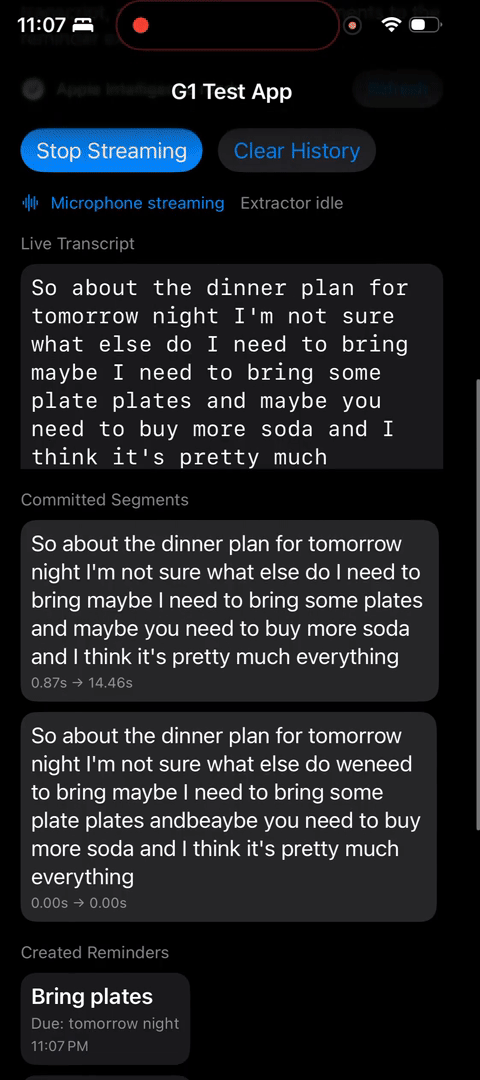
E2E works!
Tradeoffs and alternatives
If I had more time (and a bigger team), I’d want to revisit the heuristic approach — read more papers, experiment with semantic segmentation, and chat with ASR researchers. There must be a principled way to decide when a sentence is “semantically complete.”
Another axis of tradeoff is latency. In my prototype, I optimized for low latency: reminders pop up as you speak. But I could imagine a higher-latency design: wait until a conversation ends, process the entire transcript, and surface reminders as a post-hoc summary. That would circumvent the problem almost entirely, reduce distraction and might even be better for a polished product.
For now, I picked the path of least resistance: a simple threshold that keeps the system responsive and lets me move forward. But the broader design space here — sentence segmentation, semantic cut-points, latency tuning — still feels rich, and I’d love to explore it further.
Key Components
In this phase, I introduced three new pieces into the stack:
TranscriptSegmenter(perception layer): a formatted-string buffer with guardrails. Tracks elapsed time and character count, emits a CommittedSegment when thresholds are hit or text backtracks.ReminderCaptureCoordinator(intelligence layer): the glue between mic streaming, the segmenter, and the reminder extractor. It coalesces committed text, queues extraction requests, rate-limits LLM calls, and surfaces state back to the UI.ReminderCaptureTestView+ ViewModel: a dedicated playground to watch everything in action — mic controls, live transcript, committed segments, extractor status, debug summaries. This testbed has been invaluable for tuning thresholds and catching weird behaviors before shipping anything into the actual glasses UI.
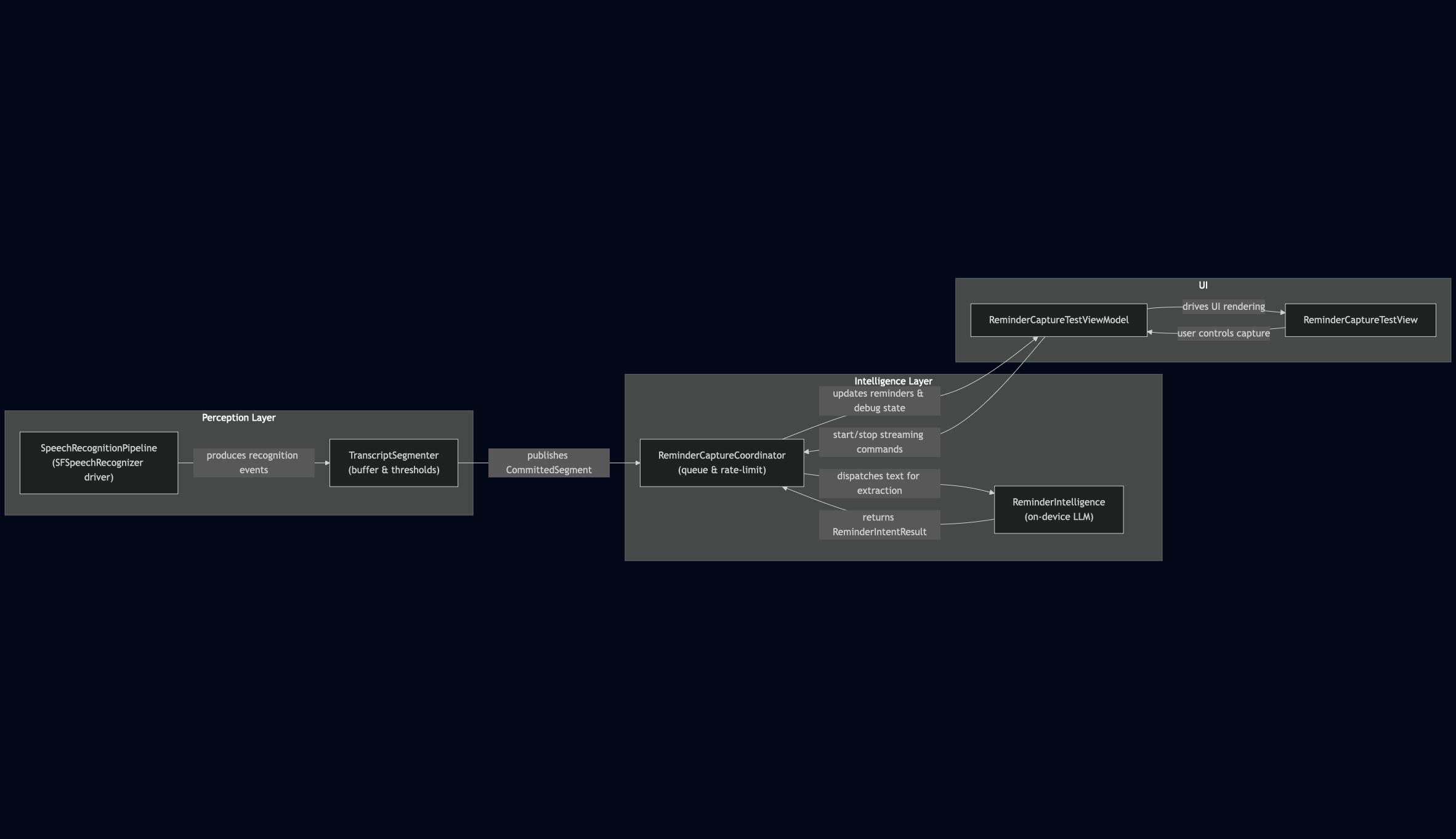
v0.3: Bridging Perception and Intelligence
V0.4: Finishing Touches
One last gap I kept running into: every LLM call forgot prior context. If someone had already said “Let’s grab dinner tomorrow” and later added “make it at 7,” the model had no memory of the first part, so it would either miss the connection or create a duplicate reminder.
The fix was to introduce a shared ConversationSummaryStore. Think of it as a running synopsis that the model itself maintains. Whenever a new utterance shifts the narrative, the agent can call an updateSummary tool to keep that synopsis fresh. That frees createReminder to stay laser-focused on capturing actual commitments.
To make this work, I built a PromptBuilder that fuses the summary with the newest transcript fragment. That way, the model always reasons with long-range context, but without me shoving full transcripts into the prompt. It stays compact, streaming-friendly, and surprisingly robust.
The other finishing touch: deduping. If someone keeps talking about dinner plans for tomorrow, we don’t want five identical reminders clogging the list. My current solution: before creating a reminder, the prompt builder queries the data store for similar reminders using cosine similarity (NLDistanceType.cosine). If it finds similar ones, those are shown to the model with explicit instructions not to recreate them.
It works well enough, though I still hope to plug in a proper on-device vector DB in the future. And if I had more time, I would add another de-duplicates step after the createReminder call, and not notify the use if there’s a duplicate.
And the last finishing touch I put in it connecting to Apple’s EventKit, which allow me to actually create reminder and read existing reminders.
Lessons Learned
1. Start simple, then build on it.
I assumed complex heuristics would tame the chaos of partial transcripts. Instead, they piled up into a brittle mess that broke with every edge case. The counterintuitive lesson: starting with one or two coarse, almost naïve rules often gets you further than an intricate web of logic. Simplicity holds up better under stress—and once it’s stable, you can always evolve it gradually.
2. Clear layering matters.
Splitting perception, presentation, intelligence, and data into distinct layers wasn’t just an architectural nicety, it was vital for fast prototyping. It let me swap in new approaches at one layer without unraveling the rest. Having test views for each layer gave me safe checkpoints, so iteration felt like stacking bricks rather than gambling the entire structure.
3. Document-oriented prompting is underrated.
Every time I made a major change, I had the model update the README and regenerate diagrams. Those artifacts weren’t just for show, they became the scaffolding for design itself. Instead of wandering around the entire codebase, the AI coder can quickly pick up the project’s structure and surgically modify the related files. It also gave me a high-level view of all components, and nudged me toward best practices. (In fact, every mermaid diagram you’ve seen in this post was generated this way.)
Closing
Afterthought began as a small hack on a pair of glasses, but it gave me a glimpse of where software is heading. I believe the future will be spatial, contextual, and agentic.
A simple reminder agent on a HUD may seem modest, but it shows how perception, intelligence, and agency can work together. For me, that’s the real takeaway — progress comes from building small pieces of the future and letting them point the way forward.